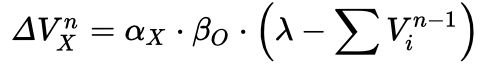I like exploring very different things and finding commonalities among them. This blog will be about comparative cognition, which normally compare across animals and humans, but because of my own background and interests I will occasionally add robots (artificial intelligence) to this comparison too.
There are a few topics this week: intelligence, tool using and mental imagery.
Chapter 35 first discussed a little bit about individual differences in animal intelligence, such as one pigeon being able to solve problems within a fraction of the time that other pigeons could, and that certain birds’ ability is correlated with their plumage colorfulness. I think these are super interesting and also largely overlooked in the other review articles we have read so far. It would be great to see more animal studies with larger sample sizes and more analyses on individual differences, because I think the variance itself could be an interesting topic to discuss.
Chapter 35 also presented various approaches to study “intelligence”, such as discrimination learning, serial reversal learning, transitive responding, mental rotation, etc. However, overall it seems like the tasks cover a wide range of different mental abilities, yet it’s somewhat unclear (and probably debatable) how “intelligence” is defined. For example, pigeons seem better than humans at mental rotation, but they are also worse than humans at many other tasks, so it’s hard to say based on these results how pigeons and humans compare in terms of “intelligence”, and it seems like “intelligence” is just an umbrella term that doesn’t really refer to anything specifically.
The evolutionary explanations of brain/intelligence development in the rest of Chapter 35 is a super interesting topic. In terms of brain sizes, the authors mentioned that larger animals have larger brains mainly because of the necessity to connect more sensory, secretory, and motor elements. However, they also said that larger animals, such as dolphins, whales, and elephants, may “benefit from the absolute size of their brains giving them a straight advantage of scale”. These seem a bit contradictory to each other, and I wonder to what extent being larger in size has a benefit on intelligence. I assume it is more difficult to study larger animals than smaller ones, though, so maybe the data is limited (?). Additionally, the authors also compared brain structures between birds and mammals, and found structures that evolved in parallel (mammalian neocortex and birds’ dorsal pallium). I’m not very familiar with birds’ brain structures, though. How much are they different from human brains? It would be nice if there is a brief introduction to this…
Bluff et al. (2007) talked about the impressive tool-oriented behaviors (TOB) in New Caledonian crows. However, the authors’ major argument was that these impressive behaviors were not due to particularly high-level cognition. They designed a ingenious studies to examine the emergence of tool using, and found that the crows didn’t show much social learning from experimenters’ tool using, but they were able to start manipulating the tool by default. They were also able to learn through mere exposure to the tools made by human. In later experiments, they demonstrated that the crows didn’t have much reasoning on the causal relationship between their tools/actions and rewards, but might be merely learning the stimuli associatively based on trial-and-error. However, here I wonder how much we could say that humans actually “understand” causal relationships rather than simply learning the associative nature between actions and stimuli. Of course, humans are more advanced in terms of making and using tools, yet it could be due to other factors, such as that we are better at imagining or mentally simulating the results based on the physical rules of the world (which we could memorize well), and that we are better at memorizing various previous solutions and generalizing to similar problems. I think humans for sure can have a lot of trouble distinguishing between causation and correlation in the real world, and sometimes people do demonstrate the same behaviors as the crows, such as trying different things to solve a problem without knowing why it should work. For example, I have tutored math and programming before, and it was extremely frequently that I saw people attempting a problem with methods that they simply knew exist (such as the solution to another problem they just encountered), but in fact completely irrelevant to the current problem. Moreover, although I could do better on these problems than the students I was tutoring (for example I might be able to find the correct method to a problem quickly and knew why I should apply a certain method to a particular problem), I am not sure if that’s only because I’ve had more practice on those problems and thus knew the associations better. Therefore, I feel like it’s hard to say that humans reason about causality because we “understand” (as opposed to that we simply make better associations and feel like we understand), even though we could reason correctly more often than animals. In other words, based on the findings in this paper, I would agree that crows may not be as good as humans in terms of reasoning about tool usage, but I am not sure that’s because crows didn’t not understand causality while we do — it could be just that we are better at making associations and transitive reasoning.
This is also relevant to the next paper on mental imagery, which entails reasoning about missing information.
The topic this week is sequential behaviors and ordinal knowledge. Notably, this is quite relevant to some of the topics we discussed before, particularly timing and counting. The serial learning paradigms reviewed in chapter 31 and 32, which presented sequential patterns to rats, seemed to be a paradigm developed based on the earlier paradigms that studied animal perception of time. For example, here the animals need to be able to discriminate and memorize stimuli occured at different times. Thus the paradigms here probably rely on rats’ ability of timing and counting, as well as other additional abilities such as memory. Therefore it seems natural that researchers found multiple cognitive processes and brain areas (basial ganglia, caudate nucleus, hippocampus, etc.) supporting sequential learning. Additionally, spatial navigation also seems to be an ability based on sequential learning, since it requires humans/animals to carry out a series of actions based on spatial cues.
In chapter 31, authors first discussed a series of experiments using a circular 8-lever (1-8) chamber with rats. They found that rats were able to extract abstract rules in behavioral patterns, including hierarchical patterns (e.g., 121 232 343…) and interleaved patterns (e.g., 182838…). It was particularly impressive that rats were also able to learn a pattern interleaved with another alternating pattern (e.g., 17283748…).
The next part discussed phrasing cues, which was somewhat confusing to me. It was quite unclear what the “cues” refer to (for example the authors said “spatial or temporal cues were placed congruent with boundaries between subpatterns”, and I’m not sure what that means, particularly the spatial cues as the patterns seemed to be temporal). But it seems like the cues (such as time interval between chunks) helped rats highlight the patterns and thus facilitated their learning. This reminds me of a personal experience relevant to chunking: I was given a door code as 331-1321, and constantly forgot it until I started to regroup it as 3311-321, which, according to this paper, can be seen as a hierarchical pattern with different subpatterns. I wonder if rats also have the ability to regroup the “incorrectly” grouped patterns.
The authors did more experiments on pattern violation to examine the factors contributing to rats’ pattern learning. In particular, rats by default seemed to rely on spatial location of the levers to remember the serial actions, rather than the position of the action in the action series. However, they were also able to learn the serial position of the violations with great difficulty. Rats also learned “runs”-phrased patterns (e.g., 1234 3456 …) more quickly than “trills”-phrased patterns (e.g., 1212 3434), which was similar to humans. I wonder if this is because the runs-phrased pattern can be seen as fewer sub-patterns than trills-phrased pattern, so they actually require less working memory. For example, you could see the runs-phrased pattern as a series of 4-digit consecutive sequences, so each 4 digits can be seen as one chunk; but for the trill-phrased pattern, it’s a series of repeated 2-digit sequences, and each 4 digits have to be separated into two chunks, so there are more chunks to memorize and thus more difficult.
In chapter 32, some of the experiment employed a spatial navigation (maze learning) paradigm to study sequential behaviors. Here, the authors discussed the possibility that rats formed a cognitive map as the spatial representation of relationships. This is actually quite relevant to what I talked about at the beginning of my blog last week, that we may process abstract relations (such as semantic concepts or social relations) as if they were spatial relations. In fact, perhaps brains could just process any type of relation in the same way for efficiency purposes, including the relations between items in sequences.
Chapter 32 also described a really interesting study comparing monkeys and pigeons, and found that for a sequence ABCDE, pigeons really learned a few rules (e.g., “respond first to A”, “respond last to E”), unlike monkeys (or us) who learned the consecutive relations between all 5 items. I wonder if this behavioral pattern of learning “if-then” rules also apply to other birds and not other primates, or if this just happens to be a non-generalizable difference between pigeons and specific primates. Additionally, I am certain that if-then rules are way easier for robots than other types of relations, since it is the most basic function of any programming languages. Just because of how basic it is, are the other types of relations we know, such as sequential or even bidirectional relations, just variants of if-then rules, or do our brains represent if-then relations and other types of relations in fundamentally different ways?
The author further showed that monkeys were able to learn not only the sequential relations between stimuli, but also the abstract concepts of numbers in terms of their relative magnitudes and the different distance between numbers. This is again connected back to the counting topic a few weeks ago. Furthermore, researchers found that the firing rate of single neurons in monkeys’ IPS encoded the magnitudes of numbers, and that the width of their tuning curves increased logarithmically with the magnitude, conforming to Weber’s law. The increased width of tuning curves could also account for the fact that primates are better at discriminating smaller numbers than larger ones. The discussions in this chapter on numerical representations are very interesting, and I wonder how it may or may not be relevant to sequential learning. As the author suggested, when learning sequential stimuli, monkeys and us actually learned the sequential relations between the stimuli, unlike pigeons who learned more about the if-then rules. Does that mean we are associating each stimulus with an ordinal position in the sequence, and could that be a necessary ability to have before developing the cognition for actual numbers and magnitudes?
These two chapters really left me with a lot of questions that I wish could be answered with more research…
The topic of this week is concepts. It has been interesting for me to think about if/how this might be related to the topics from the past weeks, including spatial, temporal and numerical cognition, and even memory. We often think of concepts organized as a big network, such as a knowledge graph (which apparently happens to be how Google Search gives you the top infobox when searching for certain concepts or people). In such an analogy, particular concepts could be seen the same as landmarks and beacons when navigating in space. Are concept organization and spatial navigation actually supported by shared brain mechanism? Some research seemed to suggest so, for example, Eichenbaum and Cohen (2014) argued that the hippocampus encodes a broad range of both spatial and nonspatial organizations, including “all manner of specific objects, behaviors, and events”. Solomon et al. (2019) also found that theta oscillations in the medial temporal lobe encodes distances in both semantic and temporal spaces. Many researchers (e.g., ) have suggested that the brain may have a cognitive map mechanism that supports all of these map-like cognition, so it would be cool if we could find out more evidence that concepts, just like landmarks in spaces, are also organized “spatially” in human and/or animal brains.
(Just one more off-topic thing as we talk about spatial cognition: I actually found out that some common robots do construct maps in their “mind” rather than only relying on GPS. For robot vacuum cleaners, they usually need to spend some time navigating the house to map the objects, obstacles and their charger, so later when they vacuum they can plan better routes based on the map, and at the end of cleaning always go back to their charger.)
The review paper from Zentall et al. (2008) covers a few types of concept learning, including perceptual concept learning (categorization based on similar physical/perceptual properties), associative concept learning (categorization of arbitrary stimuli based on their associated events), relational concept learning (learning relationships between objects), and analogical reasoning (learning relations between relations).
Perceptual concept learning is essentially testing whether or not animals could classify or tell the similarity among a few categories of stimuli, such as pictures of animals or objects. It’s interesting that pigeons found it difficult to generalize beyond the training examples of those categories, which perhaps suggest that they didn’t always learn the concepts underlying the pictures, but they rely more on superficial information from pictures themselves. This seems to be reflected well in their close-to-random accuracy (27%) when only seeing one example picture from each of the 4 categories, whereas (I believe) humans would do better. However, showing pigeons diverse examples in the same category helped them with the task. In some ways, pigeons seem to work similarly to a machine learning algorithm — they only generalize well in the testing phase after you give them representative training data, otherwise they overfit to the training data and don’t know anything else. This task also remind me of a piece of news I saw, where researchers trained pigeons to diagnose cancer and they did pretty well (although they still seemed to suffer from generalization problems). Additionally, I also wonder if pigeons do better on certain categories than others, for example, cars and chairs are both artificial objects that doesn’t exist in nature — would pigeons do worst on these? Or alternatively, would lab-raised pigeons do worse on things they have never seen in their lives, such as cats and cars but not chairs?
The next section, associative concept learning, seemed very similar to the associative learning paradigm we discussed a few weeks ago, where pigeons were able to do “if-then” tasks. Here pigeons were not only able to learn simple “if-then”s, but also more complicated associations such as “if A is associated with B, B is associated with C, then A is associated with C”. Zentall also developed a paradigm involving presence versus absence of a stimulus, and concluded that the absence response was “default”. However, I feel like it could be alternatively explained by that when the delay got too long, pigeons were confused by whether the delay counted as an absence of stimuli, and then responded correspondingly.
Relational concept learning and analogical reasoning are more difficult tasks for animals, because relations/comparisons are more abstract and independent of the perceptual properties of stimuli. The article mentioned a problem with interpreting the results (generalization is a confounding factor), but I didn’t really understand the problem or why generalization is problematic (?)… Anyway, researchers found evidence for transitive inference (A > B, B > C, thus A > C) in many animals such as rats and crows, but pigeons are not mentioned here — does that mean pigeons cannot do this? It was also super interesting that the author mentioned transitive inference could be essential for animals to learn the relative social ranks of their own or others in dominance hierarchies. This makes me wonder if all relatively non-social animals don’t have much abilities in transitive inference…
Analogical reasoning tasks involved judging whether two relations/comparisons are the same or different. The “profound disparity” between humans and apes versus all other animals was fascinating — only humans and trained apes were able to do most of the analogical reasoning tasks. However, pigeons or baboons could also do the tasks when there is a large number of stimuli being compared. I feel like this could be simply attribute to that in their experiment, the two types of stimuli (same/different) have quite obviously different perceptual patterns, such that the “same” stimulus looked a lot more organized/repetitive while the “different” stimulus looked messy, and the “same” stimulus is also topologically different from the “different” stimulus. If the pigeons simply attend to the different patterns this way, the task essentially turns into a simple perceptual match-to-sample task, rather than a relational one. The same confounding factor also applies to the similar tasks involving arrays of stimuli in Chapter 28. Both the review paper and Chapter 28 also discussed that pigeons indeed discriminate stimuli based on item variability and entropy, although I didn’t quite follow some of the relevant experiments they mentioned (e.g., Fagot, Wasserman, & Young, 2001). I think even though this is true, it is still interesting in that it perhaps mean that pigeons are able to attend to global and/or topological patterns rather than local properties of the stimuli. This is also confirmed in Brooks and Wasserman’s study (2008) mentioned in Chapter 28.
References
Eichenbaum, H., & Cohen, N. J. (2014). Can we reconcile the declarative memory and spatial navigation views on hippocampal function?. Neuron, 83(4), 764-770.
Epstein, R. A., Patai, E. Z., Julian, J. B., & Spiers, H. J. (2017). The cognitive map in humans: spatial navigation and beyond. Nature neuroscience, 20(11), 1504.
Solomon, E. A., Lega, B. C., Sperling, M. R., & Kahana, M. J. (2019). Hippocampal theta codes for distances in semantic and temporal spaces. Proceedings of the National Academy of Sciences, 116(48), 24343-24352.
Chapter 22 reviewed the history of research on timing, where researchers tried to explain timing behaviors though various perspectives. The first few studies, just like many studies from every other topic we have discussed so far, used learning paradigms. (Learning paradigms seem so powerful that they can be applied to the research of any type of behaviors.) The experiments presented here are pretty simple, though. The first study trained dogs to react with different latencies to different intervals between CS and US. The second study trained rats to make responses at different rates. The author explain this study paradigm as a type of social competition, however, if I understand the paradigm correctly, it looks like the results would have been the same whether or not the rats realized they were supposed to be competing — they might simply think their response rate should be high or low in order to to get the food, regardless of the other rat’s behaviors. The next couple of studies again showed that rats were able to discriminate different time latencies after training.
The next section provided a cognitive account for timing through internal clocks. The studies here showed more timing-related abilities animals (mostly rats) were capable of, and certain characteristics of these timing abilities (which I think are similar to humans). For example, quite a few studies (LaBarbara & Church, 1974; Libby & Church, 1974; Church & Deluty, 1977) showed that rats knew, or were able to discriminate, the amount of time passed, and that they estimated time in proportional units. Roberts and Church (1978) added breaks within the stimuli and tested rats’ responses about the duration of the stimuli. They showed that rats were able to correctly “pause” and “resume” their internal clocks and made correct responses (if I understood the study correctly). It was further shown in a lesion study that the fimbria fornix played a role in interval timing (Meck, Church & Olton, 1984). Two studies (Church, Getty & Lerner, 1976; Platt, Kuch & Bitgood) showed that rats’s time estimates were more variable for longer durations. It is interesting that these researchers also found a linear relation between the square of the difference limen and the square of the duration, but in Fig. 22.7, they seemed to have used an extremely limited number of data points (only 5) to make that claim, so I’m a little skeptical about this conclusion (for example, in the top left panel it looks like a straight line could have fit the data just as well as, if not better than, the quadratic line).
The authors discussed a bit about how subjective time varied as a function of physical time, and mentioned that Church and Deluty’s (1977) study seemed to supported that subjective time increases as a logarithm of time. If I recall correctly, however, there are a lot of studies done on human about how the events they experienced change the subjective time, and we may all have the experience that having a lot of exhausting events scheduled in a short amount of time makes us feel the day is long. So in my opinion the subject time is likely more complicated than just a simple function of the actual time — it may also be a function of our experience or memory. Investigating this in animals may be hard, but it would be extremely interesting if it could be possible. Another studies in this chapter (Church, 1980) tried to study subjective time in rats, but I feel like it is hard to reach unambiguous conclusions based on their results… Church’s study (1980) introduced retention intervals (time between stimulus and recall) changed the rats’ response pattern — they actually seemed more likely to respond at random (closer to 50%, i.e., chance, possibility of choosing “long”), so maybe they just forgot what they saw earlier. I’m not sure I understand why the author interpreted the other set of results as “forgetting did not occur on the time dimension”, since it’s also true for those results that the responses were closer to random for a longer retention interval. It seemed unclear to me whether rats actually perceived the stimulus duration differently or they just simply didn’t remember clearly…
The rest of the chapter is devoted quantitative theories for timing. The scalar timing theory wasn’t extensively described, but seemed quite simplified and doesn’t account for many phenomena. The multiple oscillator theory was a bit hard to understand but seemed better supported by data.
Chapter 24 discussed number representation. It first talked about the the ratio dependence of numerical judgements in humans and other animals, that is, the discriminating quantities is more difficult for quantities that have a close-to-1 ratio. The chapter discussed many studies that showed this phenomena in monkeys, rats, and college students. In addition to these studies, I remember learning about this in a talk, where the speaker also mentioned that in most languages of indigenous peoples, they only have small numbers (such as “one”, “two” … and it rarely surpassed “five”) and “many”. I think this is also a piece of indirect evidence that people can discriminate smaller numbers (ratios farther away from 1) better than larger numbers. This is also discussed later in this chapter, and apparently people still have an approximate number system for large quantities even it’s not in their language.
The authors also talked about studies that showed that the point of subjective equality (PSE) for both children and monkeys was closer to the geometrical mean than to the arithmetic mean. This is super interesting, and I wonder if there is an evolutionary advantage in this perception.
The semantic congruity effect is also very interesting, particularly that it was found in monkeys who did not have the semantic ability. I think this shows how mistaken a theory (the discrete code model) could be, even when it makes perfect sense based on limited human-only data. Taking the context of comparison into consideration makes a lot more sense to me (e.g., Holyoak, 1978), and I feel like another study I know of also provides insights into this issue. In Knops et al. (2009), researchers showed that mental arithmetic operations recruited brain regions that are typically involved in orienting attentions spatially, and the patterns of brain activities involved in mental arithmetic also went in different directions as people add or subtract numbers, as if they had a numerical x-axis in mind (small numbers on the left and large numbers on the right) and was spatially moving through that line as they add or subtract. This mental representation for numbers with a horizontal line may also account for the semantic congruity effect. For example, given a context or numerical comparison from 1 – 9, we might focus our attention on the 1-9 part of the numerical line. When being asked for a larger number, we might intuitively shift our attention to the right end of the axis, and it is easy to notice that 9 is the largest; however if we are only give 1 and 2, we’d need to shift our attention back to the left/smaller end of the axis, where 2 is sort of in the middle rather than the end, thus it may take more time to get there.
Another cool but very brief discussion later in this chapter is that brain systems that support numerical coding also support coding of many other continuous variables, including time, length, and size. A common neural coding has also been found for spatial, temporal, and social distances (Parkinson et al., 2014). There has been some recent discussions on a cognitive map system that acts as a basis of map-like knowledge representation, and that can be reused for organizing things including spatial, temporal, and abstract knowledge, such as semantic concepts and social networks.
Reference
Knops, A., Thirion, B., Hubbard, E. M., Michel, V., & Dehaene, S. (2009). Recruitment of an area involved in eye movements during mental arithmetic. Science, 324(5934), 1583-1585.
Parkinson, C., Liu, S., & Wheatley, T. (2014). A common cortical metric for spatial, temporal, and social distance. Journal of Neuroscience, 34(5), 1979-1987.
The topic of this week is spatial navigation in various animals, including rats, a few types of arthropods, and corvids.
First of all, I like the perspective (in Leising & Blaisdell, 2009) that you could actually view spatial navigation as a series of reinforcement learning (a “stimulus-response chain”). I have never really thought about animal navigation this way before, but this idea links to the Q learning model I talked about in Week 2, and the Q learning model actually seems to be able to explain well a few experiments mentioned in Leising and Blaisdell’s paper (2009). Here’s the formula again:
s: the state the agent is in a: an available action the agent can take r: the amount/value of reward alpha: how fast the agent learns gamma: how much the potential future rewards should be discounted; it can be 0 so the future states are not concerned Q: the perceived value associated with this particular state (s-t) and action (a-t)
Now animal navigation seems to be very similar to a Roomba robot navigating a room while cleaning the floor, or a self-driving car following the roads to get to a destination. A simplified version of navigation, the grid world, can be described by this formula. Here, a state is the location of the agent (agent = the rat, the Roomba or the car); actions are the directions the agent could possibly take in a state; rewards are the consequences that may happen, such as getting the food for rats, or dirty floor getting cleaned for a Roomba, or getting to the destination without accidents for a car (and an accident would mean a negative reward). Some of the experiments in Leising and Blaisdell’s paper (2009) fit well to the idea of a Q learning model. In the kerplunk experiment, for example, after being trained with the same maze extensively, rats strictly followed their previous route after the maze was slightly altered, while ignoring the new barrier or food in the altered maze. The Q learning formula would simulate this habitual navigation behavior too, since even after the maze was altered, the rat/agent would still think they were in the same states as they were trained before, and choose the exactly same action/direction as before. One of the basic trade-offs in reinforcement learning problems, exploration vs exploitation, was also shown in other rat studies (Calhoun, 1962; Morris, 1981) as well as ant studies (Wehner & Srinivasan, 1981; Wehner & Wehner, 1990). The rats and ants demonstrated two types of navigation behaviors in the field/water maze/desert, one is to follow the most efficient path (i.e., exploitation of previously rewarded actions), the other is to follow longer and more random paths (i.e., exploration of new territories). In reinforcement learning problems, researchers would typically need to specify an ideal ratio of exploration vs exploitation in their robots, but maybe rats also have something similar specified in their genes?
Researchers also found other learning phenomena in spatial navigation, including blocking and overshadowing, where spatial cues or landmarks serve as the stimuli. But of course, real-life spatial navigations are more complicated than what reinforcement learning (RL) models can describe. Rats showed both response learning (which can be nicely modeled by Q learning) and place learning/goal-directed strategy in studies; real-world robots also have more advanced techniques when navigating the space. Simultaneous localization and mapping (SLAM) algorithms deals with real-world spatial navigation (such as in Roomba or self-driving cars) by constructing maps given sensor input, and it works somewhat similar to hippocampus cells, which constructs cognitive maps given sensory input. I think being able to process sensor/sensory input makes a major improvement from the simplified RL models/response learning, for both rats and robots.
The vector sum model explains goal-directed navigation in more details, arguing that animals navigate based on landmarks, and weight the landmarks differently by, for example, their proximity to the goal. The differential landmark weighting may also explain the learning phenomena such as blocking and overshadowing (redundant landmarks are weighted less heavily, salient landmarks are weighted more heavily). This reminds me of the A* search algorithm, where agents use heuristics to guide their graph search. Here the goal is the find the path to a specified node in a graph, and in the context of spatial navigation, nodes in the graph can be seen as landmarks. The agent basically preprocess the graph and weight every landmark/node differently (i.e., the heuristics), and when navigating, always go to the most heavily weighted node they could access as the next step. This parallels the vector sum model exactly and works well in many real-world applications.
Chapter 19 also discussed in more details about how arthropods build “cognitive maps” based on environmental or internal cues, such as the sky (to tell directions), the optic flow (for bees to estimate distances), step counting (for ants and crabs to estimate distances), body orientation and visual cues (for crabs to tell direction and distance), skyline, landmarks/image-matching, etc. The optic flow study with bees (Srinivasan et al., 1997) seems particularly well designed, ruling out many other cues that bees could rely on, including energy expenditure, time of flying, and number of stripes passes. That said, I’m not sure if I understand correctly what optic flow means — is it like when you are on a train, outside objects of different distances seem to move at different speeds (closer objects are faster), so they create different optic flows?
Chapter 19 also talked about global and local vectors for ants’ localization, which are very interesting and raise a lot of further questions. Global vectors sound like an estimate (probably based on step counting and direction estimates) of the current position relative to the start point; local vectors seem to be another estimate based on more recent experiences such as landmarks just passed. It is impressive that they showed the ants correcting their routes based on global vectors, after using local vectors incorrectly based on a changed landmark (channel direction). It seems like behaviors based on local vectors can be better described with RL models (landmark stimulus -> response), whereas behaviors based on global vectors may be better characterized by cognitive maps. There are also a lot more questions to ask about this: how are the two types of vectors integrated together to guide the ants’ route? When there is conflict information, how do ants (or humans/other animals) decide which type of vector take over the other? How do they “realize” they have gone wrong (or do they?) based on one type of vector and subsequently refer to the other vector?
Chapter 21 discussed the food-caching behaviors in corvids, which is less related to spatial navigation, but more related to spatial memory and social cognition. Across species and seasons, animals cache different amounts of food, and some bird are able to cache thousands (!) of food items and later find them. The social aspect of caching is particularly interesting. Corvids need avoid their food being pilfered by other birds, while potentially trying to pilfer other birds’ food without being found. This almost certainly requires theory of mind to some extent, particularly given evidence such as that they protected the food when a stranger was watching but not when their partner was watching (Dally et al., 2006), and that only birds with pilfering experiences developed better counter-pilfering strategies (Clayton, 2001). I wonder if there are more studies on birds’ social cognition…
This week the articles are related to memory processes.
Chapter 13 made a good point in the beginning that human memory studies are often confounded by the previous experiences of participants, such as the memory strategies they learned and mnemonics, which vary from one individual to another. This has also been somewhat of a problem in some of our social cognition studies, when we asked participants to remember, for example, a social network. Participants came up with many different strategies and ways of visualizations, and although it’s not directly related to the questions we study, I often wonder if they were actually confounds. I wonder how other human memory researchers view or solve this problem…
Pertinent to this, the authors seem to assume that animals don’t have these kind of strategies and animal research are thus not confounded this way (he wrote “the study of human working memory is complicated by the fact that people vary considerably in the amount of pre-experimental experience … with memory strategies. … An alternative approach is to study memory processes in nonverbal organisms.”). We only know that human participants use memory strategies because they can tell us; animal subjects can’t, but that does not seem to be a good reason to assume they do not actually use memory “strategies” that vary individually. We know that animals probably don’t use any mnemonics related to languages, however, animals may also have various experience and use different non-verbal strategies to memorize things, which may still confound the studies. The author himself even mentioned a few memory strategies later in the chapter, such as animals positioning themselves towards the shown stimulus (Hunter, 1913), and pigeon having large individual differences during the delays of a memory task. Notably, one of the pigeons was clearly using a memory strategy (which amazed me) by pecking after a red sample and not pecking after a green sample, and then it performed well in the task. This is obviously an observable behavior, but we don’t really know if other pigeons had other strategies that they didn’t “tell” us. So it sounds somewhat unfair for the author to say that only human studies could be confounded by usage of different memory strategies…
I’m a bit confused by the descriptions of the delayed matching task in Skinner’s (1950) and W. A. Roberts’ (1972) studies. Based on my understanding, pigeons (in Skinner’s study) determine which comparison stimulus have the same color as the sample stimulus. The sample appears on the central button, and after a delay time, two comparison stimuli appear on the two side buttons (?). W. A. Roberts’ (1972) study is also quite unclear in that I didn’t understand why more than one response were required (what were pigeons responding to? Why was the accuracy worse when less responses were required?). The author mentioned that a number of responses were required to “initiate the delay”, which made it even more confusing… Assuming “delay” refers to the interval between the sample and comparison stimuli, then weren’t pigeons responding before the comparison stimuli even appear? What could they respond to?
The author then introduced theories concerning animal memory, including the trace strength, temporal discriminability, and association with reinforcement (none of which explain the memory process perfectly), followed by the directed forgetting paradigm, base-rate neglect and a series of related studies. It seems interesting that the paradigms here (and in other readings this week) are (almost) the same as the reinforcement/associative learning tasks we discussed last week, only with delays in the middle. Reinforcement learning is everywhere!
The next section of Chapter 13 and the other review paper (Animal models of episodic memory) both talk about episodic memory, so here I’ll refer to both of them together. I really like and agree with the Zentall’s argument that using unexpected questions is a better way to test for episodic memory, compared to the other options presented in Crystal’s paper. Most of the paradigms (What-Where-When Memory, Source Memory, Item-in-Context Memory) didn’t seem to provide compelling evidence that distinguish between semantic memory and episodic memory (mental time travel). Instead, I think results found those those learning paradigms could be perfectly explained without episodic memory, since they mostly just involve a variant of the reinforcement learning paradigm where the animal needed to figure out specific cues associated with the rewarded stimulus. The cue could involve “what”, “where”, “when”, “source”, or “context”, but there seemed to be no concrete evidence suggesting that these could not be memorized solely through semantic memory. In the Item-in-Context Memory paradigm, particularly, I believe the results could be simply explained by that rats were choosing a stimulus that were presented to them for a less number of times (blueberry was presented only once and strawberry was presented twice, so the answer was blueberry), which does not require episodic memory and does not support the author’s original hypothesis. Using unexpected questions, however, showed that pigeons and rats could actually recall what just happened (“did I just peck?” Or “was there food just now?”) in order to answer an unexpected question, without already trained extensively to answer this exact question. I also like the ingenious design of the unexpected-question experiments, which I wouldn’t see in a human study since researchers may just be lazy and ask subjects to self-report, rather than spending time on designing their study well.
Chapter 14 discussed the research on animals’ visual and auditory list memory, particularly in terms of the primacy and recency effects. The author mentioned that animal memory often show rapid forgetting within 1 minute. It makes me think that this fast forgetting could be due the abstract experimental task — probably no pigeon is genetically well-prepared to peck at buttons based on the colors they saw, since this doesn’t seem like a crucial skill for them to survive in nature. However, some abilities, such as remembering where their homes are, is quite crucial for certain pigeons and they could retain that memory for a lot longer than 1 minute, which may be due to that they are genetically programmed for that. I wonder if we can get pigeons who are superior on the delayed matching task by selectively breeding pigeons based on their performance, just like dog breeding… Of course this sounds non-practical and arguably non-ethical, but just theoretically a possible way to show that animals may have better memory on what they are genetically prepared to remember.
The topic of memory (and perhaps the topics of later weeks too) haven’t been extensively adapted to AI research yet, with the exception of the long short-term memory (LSTM) neural networks. LSTM networks are used in natural language processing, and pay “attention” to both the currently processed words (“short-term memory”) and its context (“long-term memory”). It sounds like this might be just another deep learning algorithm that only borrowed words from psychology but didn’t actually borrow much of the concept, though… Anyway, in terms of memory, robots still have a long way to go to simulate human or animal ability. It’s probably particularly interesting/hard when it comes to episodic memory — wouldn’t they need to first have a sense of self to be able to traverse back in their own time?
The readings of this week concern associative learning and casual learning. This topic is interesting!
Chapter 10 first started with discussing what properties between events makes us perceive causality in them. This includes spatial and temporal contiguity, temporal order, and contingency. Contingency seemed to be studied and modeled extensively. First, a (somewhat simplistic) rule-based approach assumed people (and animals) would count and memorize the number of occurances of events, specifically cause-effect events, cause-no-effect events, no-cause-but-effect events, and no-cause-no-effect events. Various models were proposed under this framework, but of course the criticism was that we don’t seem to do or memorize these counts. Then the Rescorla-Wagner model was proposed, which captures the process of associative learning in a nicer trial-by-trial way:
V: associative strength for cue X on Trial n alpha: cue associability, between 0 and 1 beta: outcome associability, between 0 and 1 lambda: > 0 if the outcome occurs on that trial, or 0 if not
At this point I started to realize that “associative learning” (AL) actually sounds like the same thing as what I knew as “reinforcement learning” (RL) (although after Googling I’m not so sure any more…), and the Rescorla-Wagner model sounds like conceptually similar to a Q learning model. The only difference may be that associative learning (as its name suggests) and the Rescorla-Wagner model seems to emphasize the associative aspect between the cues and the outcomes, while reinforcement learning models seems to emphasize the actions an agent could take in particular states, and the value (or amount of rewards) associated with that action. This is the Q learning model I’m more familiar with:
s: the state the agent is in a: an available action the agent can take r: the amount/value of reward alpha: how fast the agent learns gamma: how much the potential future rewards should be discounted; it can be 0 so the future states are not concerned Q: the perceived value associated with this particular state (s-t) and action (a-t)
The two formulas looks quite different at first sight, but the underlying concepts are so similar that I’m sure they could be incorporated into the same theoretical framework in some way (i.e., they are likely the same idea written in different ways). First, both models assume that the agent only maintain/memorize one value (the association strength V, or the Q value) for a cue-outcome or state-action-reward association, which I think is the major difference between this framework and the rule-based approach. Each time the agent observe a new association, this newly learned association is only updates the last representation the agent has, and is independent of any other representations before the last one (i.e., it’s a Markov process, but the rule-based approaches are not). Second, reward and state-action combination in the RL model corresponds almost exactly to cue and outcome in AL, except that they may emphasize on different aspects of the same thing (for example, RL assumes actions are things the agent could choose whereas in AL cues are not chosen, but we could still model them in exactly the same way regardless of this conceptual difference). Third, Q learning differentiates state and action for more convenience in processes such as the Grid World, where in different states (here a state is just the position an agent travels to in the Grid World) different actions can be taken and have different consequences. But of course they could also be combined to one thing, which corresponds to cues in AL. Forth, the learning rate alpha and the discounting factor gamma are just optional parameters in the RL formula, and the AL formula above just simplified the situation to a fixed alpha and gamma = 0. Later in the chapter the authors explained extinction, which could also be captured by the learning rate here — the learning rate has an effect of placing lower weight on temporally older observations, thus C-E then C-NoE resulted in a weak response, while C-NoE then C-E resulted in a strong response. The learning rate also seems to account for “high- or low-activation memory states” mentioned later in the chapter.
I believe people have found neural evidence related to reinforcement learning, for example, the firing rate of dopamine neurons seemed to correspond to how close the newly learned value was to the previous value (e.g. Montague, Dayan & Sejnowski, 1996). This seems to support the RL/AL approach rather than the rule-based approach.
To explain backward blocking, another comparator hypothesis was purposed, which assumes that we track 3 types of information in AX-outcome training (where A and X are both cues): A-O association, X-O association, and A-X association. However I feel like this theory doesn’t sound flawless to me. The authors did not specify how the cues were presented to subjects, but I think there are two possibilities: 1) A and X are clearly separable and easily seen as two stimuli, or 2) it’s somewhat ambiguous whether A and X are two stimuli, or different parts of the same stimulus (for example if A and X are two parts of one picture presented on the screen at the same time; see the picture below). I feel like the two ways of stimuli presentation shouldn’t make a huge difference in subjects’ behaviors (I could be wrong though, I guess this is testable). Moreover, there are cases where the “one” stimulus could be separate into not just A and X but more parts, and you wouldn’t know which is A and which is X before you see the separation. However, the comparator hypothesis assumes that we have separate representations for A and X since the beginning (i.e., the AX-outcome phase), which wouldn’t be feasible for a stimulus like the picture below — when it’s presented as a whole, whether and how one separates them is completely subjective, until we actually see the A-O or X-O associations later. It’s hard to imagine that in this case blocking wouldn’t happen, yet it doesn’t seem like the comparator hypothesis would be able to explain this well (for example, do we assume an A-X association arbitrarily here or do we track all of the possibilities (which could be a huge number)? If we do make assumptions of what A is and what X, what if our assumption turns out to be wrong later?). I believe the associative learning/reinforcement learning model may explain this better.
This thing could be seen as a single stimulus, or 4 stimuli (4 rectangles), or 2 stimuli (left and right sides)
The authors mentioned that a lot of these studies were done with animals. I wonder for these basic conditioning studies, whether there is any difference at all between humans and those animals, or different animal species…
—
Now we finally move on to the actual topic of this week, causal learning. I found it interesting that all of the earlier stuff were (or could be) modeled with RL models, but in causal learning, things are more likely (and easily?) to be modeled with Beyesian models, as if they were inherently different from each other, even though the authors discussed how they could be the same.
Both chapters discussed heavily about the relations between associations and causality, which I found very insightful and inspiring. I haven’t thought about it too much before but have read an article a while ago which I think talked about how causality could be just a special subset of association (i.e., a causation is always a type of association, but associations are not always causations). For example, causations could be seen as just directional associations such that one event always follow the other with a high probability, rather than the other way around. I feel like everything discussed in these two chapters would still hold true if words like “causation” are replaced by “directional association”, but of course the case of causality is so significant it deserved its own word.
This also makes me wonder if and how much our brain actually distinguish between associations and causality. I’m not sure if anyone has done neuroscientific studies on this (or how it could be done), but it would be fascinating if there is.
Chapter 11 presented a series of rat studies that showed their understanding of causal relationships. I really like how this chapter is written — it was pretty clear and easy to follow, and whenever I had a question about something in my mind it’s almost always answered very soon in the text.
It’s particularly interesting (and makes sense) that rats (and us) see our own actions as special among all causal events. I think understanding causality and acting based on it are definitely quite essential skills to have evolutionarily. Moreover, our understanding of causality is likely only useful if we are able to make decisions on what to do based on it, for example we should be able to initiate a causal chain with our own action; if we understand causality but can’t act accordingly, then the understanding is probably useless and the nature wouldn’t let us spend the cognitive resource to keep that ability. The understanding of causality and the mentality of seeing our own actions as independent and deterministic are probably also crucial to some advanced skills such as tool using and tool making — to make complex tools, we’d need to be able to deduce a series of consequences from both our own actions and the mechanisms within the tools themselves. Given how complicated human-made tools has become, it’s no wonder that we are causal agents par excellence.
It is also kind of mind-blowing that our perception of causality is actually the basis of all empirical sciences, and experimental manipulations in science are basically our “self-generated actions”, which as we understand is independent and deterministic, and we then observe the results to find out the underlying causal relationships between things. Do animals also do science experiments to some extent?
References
Montague, P. R., Dayan, P., & Sejnowski, T. J. (1996). A framework for mesencephalic dopamine systems based on predictive Hebbian learning. Journal of neuroscience, 16(5), 1936-1947.
Donald Blough’s chapter talked about a series of experiments that measured pigeons’ reaction times to gain insights into their visual perception, attention and decision-making. He also contrasted some parts of the results to human research and it yielded interesting insights.
He started with a few experiments on visual perception and visual search. In the first study, pigeons were put in dark chambers and pecked at a spot of various luminance for food rewards. The data showed an interesting pattern:
Point A, as the author argued, showed the dissociation between the scotopic (rod) and the photopic (cone) system, which was later replicated in human visual system too (!).
This study is simple, but the findings are fascinating (especially that people later found the same phenomenon in humans). I do wonder, though, whether using only 3 birds as subjects usually yield reliable data in animal research. I understand that each of them completed a huge number of trials, but I still wonder what if there are individual differences… Are the results from 3 birds usually generalizable enough?
The article then talked about visual search experiments, and I found the comparison of search asymmetry between pigeons and humans particularly interesting. For humans, it was obviously easier to find, for example, one Q in many Os, compared to one O in many Qs, as the target (Q) has a distinctive feature while the distractor (O) does not. However, pigeons did not show this search asymmetry and had similar performance for both. The author argued that besides species difference, another possibility is that humans had way more experiences encountering similar symbols in daily life through reading, and the search asymmetry (or the lack or it) may simply reflect the different perceptual experiences between pigeons and humans.
I think this possibility the author raised could be tested through experiments. For example, instead of artificial symbols, make the subjects (both pigeons and humans) distinguish between something pigeons have more experiences with but humans don’t, such as seeds of different shapes. Another possibility is to conduct the same experiment on humans who don’t have any reading experiences, either adults or kids who haven’t learned reading. If pigeons show more search asymmetry with stimuli they are more familiar with, and/or humans who lack experiences in reading show less search asymmetry with the symbols they are not familiar with, it would indicate that the author may be right. I wonder if there are already studies that have tested the author’s hypothesis.
The author then discussed the impact of prior beliefs or expectations on the RT to a stimulus. Same as humans, pigeons responded faster to a target that was same (rather than different) as the previous one, or a target that was primed by another signal. This effect is similar to the effect of reducing the target-distractor similarity, so they conducted two further experiment to explore the relation between expectation and recognition. With the reaction time data, they concluded that the priming effect is likely just tuning the pigeon’s (or human’s) attention to certain features of the search image.
One complaint I have with all of the figures so far is that none of them included an error bar, and the author didn’t include any information on the statistics (e.g., standard error) either. It is hard to make an inference from these figures. In particular, in Fig. 6.3, where the author mentioned that the asymmetry for pigeons is the opposite of humans, the pigeon data in the figure didn’t actually show much asymmetry, and it is very hard to make the author’s conclusion without knowing if the difference is simply due to error. Same thing applies to Fig. 6.6 left panel, where the non-target orientation curve looks quite flat, while the author claimed there was a difference (left side was lower). The author himself also critiqued later that “researchers almost always present RT measurements as averages“, but this is exactly what he did too in the first part of this article…
The next section of this article explored the distributions and models for RT rather than just presenting the averages. Importantly, the RT distributions revealed data patterns that we wouldn’t be able to tell through just the means. First, it showed that pigeons sometimes “fast guessed” the answer without “thinking” as soon as the stimulus appeared. Second, the difference between RT distributions for different stimuli revealed that pigeons indeed discriminate the stimuli successfully.
The author further studied RT distributions by modeling them with first an exponential function plus a Gaussian function (“ex-Gaussian”), and then a random walk model (RWP). Ex-Gaussian modeling found that the RT differences between different levels of target-distractor (T-D) similarity is only determined by the exponential decay constant, indicating the T-D similarity only affected the momentary probability of target detection. The RWP model further quantified the impact of T-D similarity on RT. Specifically, two parameters (step size and bias) of this RT model was linked to changes in T-D similarity and rewards, respectively. The author also further discussed the Pavlovian association between stimulus and rewards, as reflected in the RT data.
One thing I always wonder about computational models for cognition is that you might never know if they are “correct”, or if the process happens in the model and the process happens in the brain are actually completely different, but they just happened to yield superficially similar result distributions — after all, an infinite number of different models could yield superficially similar results, given limited amount of input. It is true that computational modeling gives us new insights to the data, but I was also somewhat unsure whether or not they also provide us accurate knowledge about the brain, unless this knowledge is confirmed through other ways…
–
Now here is a huge digress from the actual paper. I initially put this part at the beginning, but ended up writing too much about it so I decided to move it to the end. I did spend quite a while thinking about this and enjoyed the process, so I hope you don’t mind.
As I write this, I just realized this is the first real animal research paper I have ever read (if talks and news articles that summarize animal research don’t count). I really want write about a rather small thing in this article I found interesting. The author just briefly mentioned this which intrigued me:
…birds peck at the target with high probability and great persistence, even when food is delivered on fewer than 10% of the target presentations. This procedure makes possible experimental sessions of 1000 or more trials…
Judging by his tone and the rest of this article, I guess this fact is probably common sense for animal researchers, but still quite surprising to me who have only run studies with human subjects. If we run an experiment of more than 100 or 200 trials, the data would start to look funny because our participants sometimes spend 3 minutes on a normally 20-second trial for no obvious reason, or just stop trying and sleep on the desk for 40 minutes (yes, this happens). Moreover, these were after we asked participants to leave their phones outside the testing room — I have no doubt that the data would be even more terrible if we didn’t.
I’m not trying to blame the participants, though — I’m not sure I can sit in a room doing those repetitive trials for 100 times myself. But a pigeon can. A robot (i.e., a computer program) can do even better — it can do anything for however many times you tell it to. Yet we think humans are intelligent and robots are stupid. It makes me wonder if “getting bored” is actually an indicator for higher level cognition, and the inability to focus on repetitive stimuli is an evolutionarily advantageous skill.
I’m not sure if this could be a testable hypothesis, but it would actually makes sense if true. The other side of “getting bored” is that as humans, we strongly prefer novelty and complexity. We have this preference since infancy as if it’s programmed into our gene: Infants spend more time looking at novel complex objects, and get bored or habituated to familiar and repeated stimuli (e.g., Oakes, 2010). As I think about it, this preference is quite likely evolutionarily advantageous — it might have allowed our ancestors to be able to create and use tools or solutions that were non-existing before, which is quite a distinction between us and other species.
(So I guess our undergrad participants not doing so well in studies might have something to do with how humans evolved to be intelligent… Hmmmm.)
I think this is still relevant to robots, too. AI researchers have been to making their algorithms behave more like human, intentionally or unintentionally, to achieve better performance on certain tasks. As I’ll discuss later, there definitely are similarities between algorithms and real biological processes, including the above one, but most of the time they are still quite far away from each other, even when they have the same name (e.g., “neural networks”). Introducing biological and psychological concepts into AI research is quite fascinating and has been proved successful (e.g., the attention mechanism used in language translation), which why I would like to include the “robots” part in this blog.
The preference for novel complex stimuli versus repetitive stimuli does remind me of a few things in AI research. For example, reinforcement learning algorithms are perhaps some of the algorithms that are most closely related to the actual cognitive phenomenon in human and animals. In AI-based reinforcement learning, the trade-off between exploration and exploitation is basically a preference your robot would have for exploring unknown territories versus just exploiting known areas that are promising. In this situation, a pigeon may lean to exploitation of an existing solution in the realm of all possible solutions, but a human may not be so interested.
Similarly, a lot of computer vision (i.e., highly automated image processing) algorithms are also set to “prefer” complex features of images, such as edges and corners, instead of flat areas with no intensity change (“prefer” here means they care about certain features in an image and ignore the others, in order to recognize the image or extract information from it). This also ends up making an algorithm perform similarly to the visual perception of human.
I wonder if making more algorithms “prefer” novelty and complexity would improve their performance. For example, when training a neural network, would it be possible to somehow (semi-manually?) put more weight on features that are rarely seen, in order to increase generalizability? Maybe that could be something to try.
References
Blough, D. S. (2006). Reaction-time explorations of visual perception, attention, and decision in pigeons. Comparative cognition: Experimental explorations of animal intelligence, 89-105.
Oakes, L. M. (2010). Using habituation of looking time to assess mental processes in infancy. Journal of Cognition and Development, 11(3), 255-268.Chicago