The readings of this week concern associative learning and casual learning. This topic is interesting!
Chapter 10 first started with discussing what properties between events makes us perceive causality in them. This includes spatial and temporal contiguity, temporal order, and contingency. Contingency seemed to be studied and modeled extensively. First, a (somewhat simplistic) rule-based approach assumed people (and animals) would count and memorize the number of occurances of events, specifically cause-effect events, cause-no-effect events, no-cause-but-effect events, and no-cause-no-effect events. Various models were proposed under this framework, but of course the criticism was that we don’t seem to do or memorize these counts. Then the Rescorla-Wagner model was proposed, which captures the process of associative learning in a nicer trial-by-trial way:
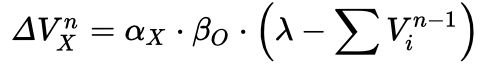
alpha: cue associability, between 0 and 1
beta: outcome associability, between 0 and 1
lambda: > 0 if the outcome occurs on that trial, or 0 if not
At this point I started to realize that “associative learning” (AL) actually sounds like the same thing as what I knew as “reinforcement learning” (RL) (although after Googling I’m not so sure any more…), and the Rescorla-Wagner model sounds like conceptually similar to a Q learning model. The only difference may be that associative learning (as its name suggests) and the Rescorla-Wagner model seems to emphasize the associative aspect between the cues and the outcomes, while reinforcement learning models seems to emphasize the actions an agent could take in particular states, and the value (or amount of rewards) associated with that action. This is the Q learning model I’m more familiar with:

a: an available action the agent can take
r: the amount/value of reward
alpha: how fast the agent learns
gamma: how much the potential future rewards should be discounted; it can be 0 so the future states are not concerned
Q: the perceived value associated with this particular state (s-t) and action (a-t)
The two formulas looks quite different at first sight, but the underlying concepts are so similar that I’m sure they could be incorporated into the same theoretical framework in some way (i.e., they are likely the same idea written in different ways). First, both models assume that the agent only maintain/memorize one value (the association strength V, or the Q value) for a cue-outcome or state-action-reward association, which I think is the major difference between this framework and the rule-based approach. Each time the agent observe a new association, this newly learned association is only updates the last representation the agent has, and is independent of any other representations before the last one (i.e., it’s a Markov process, but the rule-based approaches are not). Second, reward and state-action combination in the RL model corresponds almost exactly to cue and outcome in AL, except that they may emphasize on different aspects of the same thing (for example, RL assumes actions are things the agent could choose whereas in AL cues are not chosen, but we could still model them in exactly the same way regardless of this conceptual difference). Third, Q learning differentiates state and action for more convenience in processes such as the Grid World, where in different states (here a state is just the position an agent travels to in the Grid World) different actions can be taken and have different consequences. But of course they could also be combined to one thing, which corresponds to cues in AL. Forth, the learning rate alpha and the discounting factor gamma are just optional parameters in the RL formula, and the AL formula above just simplified the situation to a fixed alpha and gamma = 0. Later in the chapter the authors explained extinction, which could also be captured by the learning rate here — the learning rate has an effect of placing lower weight on temporally older observations, thus C-E then C-NoE resulted in a weak response, while C-NoE then C-E resulted in a strong response. The learning rate also seems to account for “high- or low-activation memory states” mentioned later in the chapter.
I believe people have found neural evidence related to reinforcement learning, for example, the firing rate of dopamine neurons seemed to correspond to how close the newly learned value was to the previous value (e.g. Montague, Dayan & Sejnowski, 1996). This seems to support the RL/AL approach rather than the rule-based approach.
To explain backward blocking, another comparator hypothesis was purposed, which assumes that we track 3 types of information in AX-outcome training (where A and X are both cues): A-O association, X-O association, and A-X association. However I feel like this theory doesn’t sound flawless to me. The authors did not specify how the cues were presented to subjects, but I think there are two possibilities: 1) A and X are clearly separable and easily seen as two stimuli, or 2) it’s somewhat ambiguous whether A and X are two stimuli, or different parts of the same stimulus (for example if A and X are two parts of one picture presented on the screen at the same time; see the picture below). I feel like the two ways of stimuli presentation shouldn’t make a huge difference in subjects’ behaviors (I could be wrong though, I guess this is testable). Moreover, there are cases where the “one” stimulus could be separate into not just A and X but more parts, and you wouldn’t know which is A and which is X before you see the separation. However, the comparator hypothesis assumes that we have separate representations for A and X since the beginning (i.e., the AX-outcome phase), which wouldn’t be feasible for a stimulus like the picture below — when it’s presented as a whole, whether and how one separates them is completely subjective, until we actually see the A-O or X-O associations later. It’s hard to imagine that in this case blocking wouldn’t happen, yet it doesn’t seem like the comparator hypothesis would be able to explain this well (for example, do we assume an A-X association arbitrarily here or do we track all of the possibilities (which could be a huge number)? If we do make assumptions of what A is and what X, what if our assumption turns out to be wrong later?). I believe the associative learning/reinforcement learning model may explain this better.

The authors mentioned that a lot of these studies were done with animals. I wonder for these basic conditioning studies, whether there is any difference at all between humans and those animals, or different animal species…
—
Now we finally move on to the actual topic of this week, causal learning. I found it interesting that all of the earlier stuff were (or could be) modeled with RL models, but in causal learning, things are more likely (and easily?) to be modeled with Beyesian models, as if they were inherently different from each other, even though the authors discussed how they could be the same.
Both chapters discussed heavily about the relations between associations and causality, which I found very insightful and inspiring. I haven’t thought about it too much before but have read an article a while ago which I think talked about how causality could be just a special subset of association (i.e., a causation is always a type of association, but associations are not always causations). For example, causations could be seen as just directional associations such that one event always follow the other with a high probability, rather than the other way around. I feel like everything discussed in these two chapters would still hold true if words like “causation” are replaced by “directional association”, but of course the case of causality is so significant it deserved its own word.
This also makes me wonder if and how much our brain actually distinguish between associations and causality. I’m not sure if anyone has done neuroscientific studies on this (or how it could be done), but it would be fascinating if there is.
Chapter 11 presented a series of rat studies that showed their understanding of causal relationships. I really like how this chapter is written — it was pretty clear and easy to follow, and whenever I had a question about something in my mind it’s almost always answered very soon in the text.
It’s particularly interesting (and makes sense) that rats (and us) see our own actions as special among all causal events. I think understanding causality and acting based on it are definitely quite essential skills to have evolutionarily. Moreover, our understanding of causality is likely only useful if we are able to make decisions on what to do based on it, for example we should be able to initiate a causal chain with our own action; if we understand causality but can’t act accordingly, then the understanding is probably useless and the nature wouldn’t let us spend the cognitive resource to keep that ability. The understanding of causality and the mentality of seeing our own actions as independent and deterministic are probably also crucial to some advanced skills such as tool using and tool making — to make complex tools, we’d need to be able to deduce a series of consequences from both our own actions and the mechanisms within the tools themselves. Given how complicated human-made tools has become, it’s no wonder that we are causal agents par excellence.
It is also kind of mind-blowing that our perception of causality is actually the basis of all empirical sciences, and experimental manipulations in science are basically our “self-generated actions”, which as we understand is independent and deterministic, and we then observe the results to find out the underlying causal relationships between things. Do animals also do science experiments to some extent?
References Montague, P. R., Dayan, P., & Sejnowski, T. J. (1996). A framework for mesencephalic dopamine systems based on predictive Hebbian learning. Journal of neuroscience, 16(5), 1936-1947.

“At this point I started to realize that “associative learning” (AL) actually sounds like the same thing as what I knew as “reinforcement learning” (RL) (although after Googling I’m not so sure any more…), and the Rescorla-Wagner model sounds like conceptually similar to a Q learning model.”
They are highly similar, but RL models seem to be about instrumental action, whereas AL models can be applied both to Pavlovian (allocentric) and instrumental (egocentric) relations.
“However I feel like this theory doesn’t sound flawless to me. The authors did not specify how the cues were presented to subjects, but I think there are two possibilities: 1) A and X are clearly separable and easily seen as two stimuli, or 2) it’s somewhat ambiguous whether A and X are two stimuli, or different parts of the same stimulus (for example if A and X are two parts of one picture presented on the screen at the same time; see the picture below).”
The points you raise here and in the text that follows make a very good point. We will discuss in class the comparator hypothesis and its relation to traditional associative learning models (e.g., the RW model), and how the empirical work has been conducted.
LikeLike